[PostgreSQL 테스트] regression.out을 JUnit 형식으로 변환하기 - 테스트 실패를 한눈에 파악하자
안녕하세요!
지난 글에서는 PostgreSQL regression 테스트의 구조와 결과 파일들을 살펴봤어요.
그럼 본격적으로 어떻게 효율을 개선하게 되었는지 써나가 볼게요.
make check 를 통해서 테스트를 해서 결과를 보면
테스트 결과 파일(regression.out)이 너무 길고 복잡해서, 어느 테스트가 실패했는지, 그리고 왜 실패했는지 파악하기가 정말 힘들었거든요.
특히 regression.diffs 파일을 열어서 일일이 확인하는 방식은 너무 비효율적이었습니다. 그래서 생각한 거죠.
문제 인식: 테스트 결과를 보는 게 너무 힘들다
- 어떤 테스트가 실패했는가
- 왜 실패했는가
- 몇 개의 항목에서 실패했는가
이 세 가지를 한눈에 파악할 수 있어야 하는데, 기존 방식으로는 불가능했어요.
그리고 Jenkins 같은 CI/CD 도구에서는 보통 JUnit XML 형식의 테스트 결과를 읽어요. 그 형식으로 변환할 수 있다면, 웹 대시보드에서도 깔끔하게 볼 수 있을 거라 생각했습니다.
해결 방법: JUnit XML 형식 변환
문제를 명확히 한 후, 다음과 같은 계획을 세웠어요.
목표: regression.out과 regression.diffs 파일을 읽어서, JUnit XML 형식으로 변환하되, 실패 메시지를 단순한 diff가 아닌 요약된 형태로 보여주는 것.
1단계: 기본 구조 파악
먼저 PostgreSQL 테스트 결과가 어떤 구조인지 파악했어요.
# regress 관련 파일 구조
src/test/regress/
├── regression.out # 테스트 실행 결과 (plain text)
├── regression.diffs # 실패한 테스트의 diff
└── results/
├── aggregates.out # aggregates 테스트 결과
├── bitmapops.out # bitmapops 테스트 결과
└── ... (각 테스트별 결과 파일)
regression.out 파일의 형식:
# 병렬 테스트 그룹
parallel group (17 tests): portals_p2 combocid advisory_lock ...
ok 1 aggregates
ok 2 allTypes
not ok 3 bitmapops ... 2 seconds
...
ok: 성공한 테스트not ok: 실패한 테스트- 숫자: 테스트 번호
- 이름: 테스트 이름
2단계: Python 스크립트 작성
Python으로 변환 스크립트를 작성했습니다. 핵심 로직은:
regression.out파일에서 각 테스트의 상태 파싱regression.diffs파일에서 실패 원인 추출- JUnit XML 형식으로 생성
- 실패 메시지 요약: 단순 diff가 아닌 핵심 내용만 추출
# 핵심 로직 예시
def parse_regression_output(file_path):
tests = []
with open(file_path, 'r') as f:
for line in f:
if line.startswith('ok '):
# 성공 테스트 파싱
tests.append(parse_ok_line(line))
elif line.startswith('not ok '):
# 실패 테스트 파싱
tests.append(parse_not_ok_line(line))
return tests
def extract_failure_summary(diff_content):
"""
diff 내용에서 핵심 실패 원인만 추출
- ERROR: 라인 우선 노출
- 값 불일치 (- vs +) 비교
- 너무 길면 요약
"""
summary = []
# 1. ERROR 라인 찾기
for line in diff_content.split('\n'):
if 'ERROR:' in line:
summary.append(f"[ERROR] {line.strip()}")
# 2. 값 불일치 찾기
lines = diff_content.split('\n')
for i, line in enumerate(lines):
if line.startswith('-') and i+1 < len(lines) and lines[i+1].startswith('+'):
expected = line[1:].strip()
actual = lines[i+1][1:].strip()
if expected != actual:
summary.append(f"[MISMATCH] Expected: {expected}")
summary.append(f"[MISMATCH] Actual: {actual}")
return '\n'.join(summary)
3단계: 복잡했던 부분들
실제 구현 과정에서 마주친 문제들이 몇 가지 있었어요.
문제 1: 테스트 그룹명이 너무 길다
regression.out에서:
parallel group (17 tests): portals_p2 combocid advisory_lock xmlmap functional_deps tsdicts guc dependency equivclass select_views window bitmapops cluster indirect_toast foreign_data foreign_key tsearch
이건 전체 그룹 이름이에요. 근데 실제로는 개별 테스트 (bitmapops)만 필요했는데, JUnit의 classname에 전체 그룹명을 넣으니까 너무 길어졌어요.
해결책: 테스트 이름에서 테스트 타입(sequential vs parallel)과 개별 테스트명만 추출해서 classname을 만들었습니다.
<testcase classname="parallel.bitmapops" name="bitmapops" />
대신 그룹 정보는 XML의 properties 영역에 따로 저장했어요.
문제 2: 실패 원인이 여러 가지다
테스트가 실패하는 이유가 다양했어요:
- 계산 로직 차이: 기대값 1000인데 실제 2828.97…
- NULL 반환: 값을 반환해야 하는데 빈 값
- SQL 표준 규칙 변경: 이전에는 되던 쿼리가 이제는 ERROR
- 실행 계획 변경: 같은 결과지만 쿼리 실행 순서가 다름
단순히 diff를 그대로 넣으면 이런 차이를 구분하기 어려웠어요.
해결책: 각 diff 청크(chunk)마다 실패 유형을 분류했습니다.
def classify_failure_type(diff_chunk):
if 'ERROR:' in diff_chunk:
return '[RUNTIME_ERROR]'
elif diff_chunk.count('-') > 5 and diff_chunk.count('+') > 5:
return '[QUERY_PLAN_CHANGED]'
else:
return '[VALUE_MISMATCH]'
문제 3: 긴 diff를 어떻게 정리할까
하나의 테스트에서 diff가 수백 줄일 수도 있어요. 이걸 전부 JUnit <failure> 태그에 넣으면 읽기가 너무 힘들었어요.
해결책: 계층적 구조로 만들었습니다.
[FAIL] aggregates
--------------------------------------------------
(1) VALUE MISMATCH (Line 2122)
EXPECTED: 1000
ACTUAL: 2828.968253968254000
QUERY: select sum(1/ten) filter (where ten > 0) from tenk1;
(2) RUNTIME ERROR (Line 3031)
ERROR: column "agg_sort_order.c2" must appear in the GROUP BY clause...
--------------------------------------------------
[FULL DIFF BELOW]
... (실제 diff 내용) ...
이렇게 하니 처음에는 요약을 보고, 필요하면 아래 전체 diff를 확인할 수 있게 됐어요.
실제 변환 결과: 어떻게 달라졌나
변환 전후를 비교해보면:
변환 전 (regression.diffs)
Test 'aggregates' failed.
--- DIFF ---
diff -U3 /home/.../expected/aggregates.out /home/.../results/aggregates.out
--- /home/.../expected/aggregates.out 2026-01-22 07:03:35.000000000 +0000
+++ /home/.../results/aggregates.out 2026-01-27 06:37:10.482541734 +0000
@@ -2122,9 +2122,9 @@
select sum(1/ten) filter (where ten > 0) from tenk1;
- sum
-------
- 1000
+ sum
+-------
+ 2828.968253968254000
(1 row)
...
(수백 줄)
변환 후 (JUnit XML)
<?xml version="1.0" encoding="UTF-8"?>
<testsuite name="PostgreSQL Regression Tests" tests="3" failures="1" errors="0">
<testcase classname="sequential.aggregates" name="aggregates" time="2.543">
<failure message="VALUE MISMATCH detected in 2 locations">
[FAIL] aggregates
--------------------------------------------------
(1) VALUE MISMATCH (Line 2122)
EXPECTED: 1000
ACTUAL: 2828.968253968254000
QUERY: select sum(1/ten) filter (where ten > 0) from tenk1;
(2) RUNTIME ERROR (Line 3031)
ERROR: column "agg_sort_order.c2" must appear in the GROUP BY clause...
--------------------------------------------------
[FULL DIFF BELOW]
diff -U3 /home/.../expected/aggregates.out ...
</failure>
<system-out>Test output and logs here</system-out>
</testcase>
</testsuite>
OpenSouurce 인 TestcaseCraft 에서 이 JUnit XML을 읽으면:
- 테스트 이름, 상태, 실행 시간이 한눈에 보임
- 실패 이유가 요약되어 있어서 바로 이해 가능
- 필요하면 전체 diff도 확인 가능
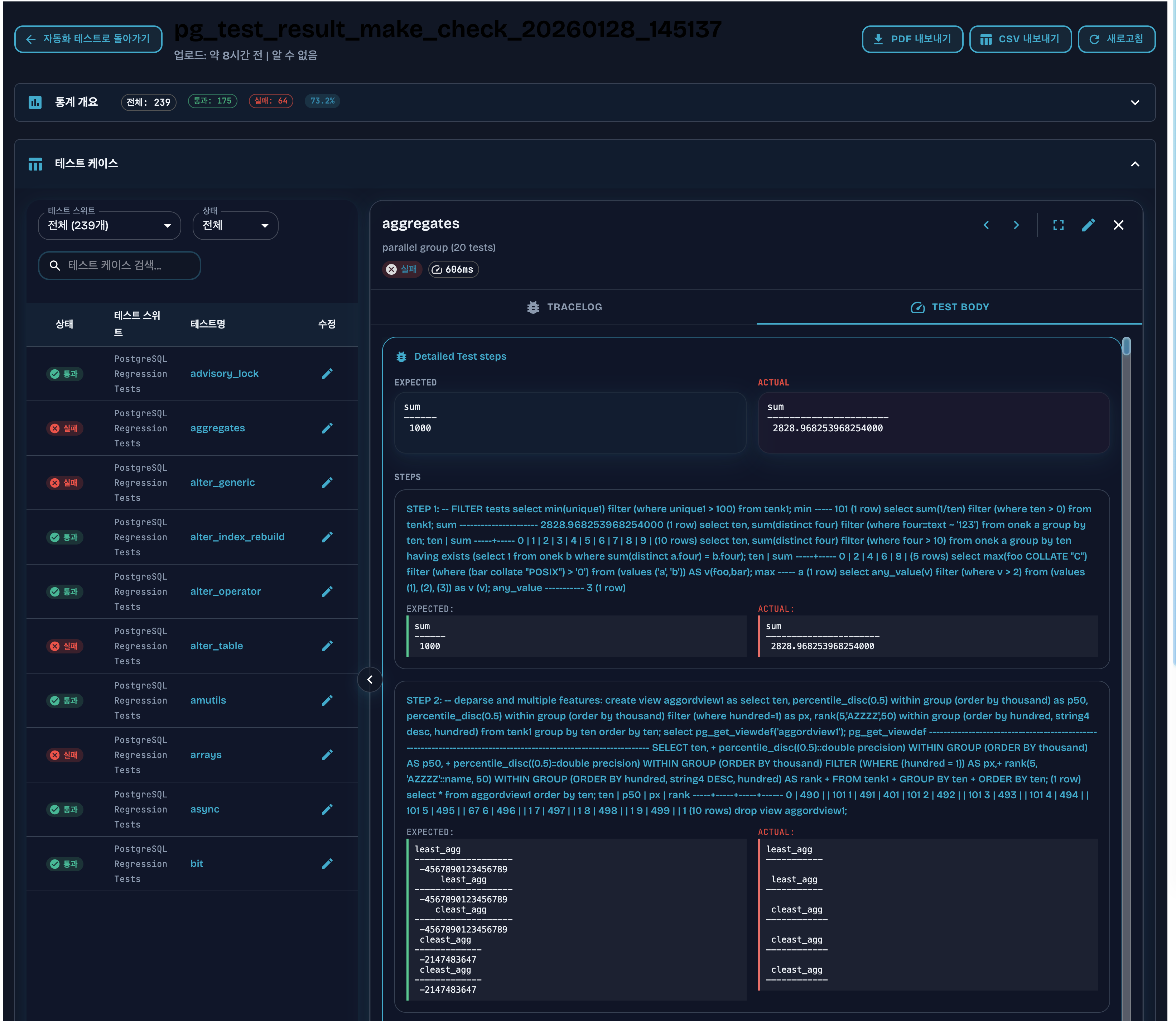
보기쉽죠..? 나만 느끼는건아니죠?
처음에 단순히 “pass/fail”만 잘 나오면 된다고 생각했던 것과 달리, 실제로는 테스트 그룹(sequential vs parallel), 실행 시간, 테스트 번호, 로그 파일 위치 같은 메타데이터들이 전부 있어야 비로소 테스트 결과를 제대로 이해하고 활용할 수 있다는 거였어요.
이런 정보들을 JUnit XML의 <properties> 영역에 담아두니, 나중에 분석하거나 실패 패턴을 추적할 때 훨씬 덜 헤매게 되더라고요.
또한 기술적으로 “변환이 된다”는 것과 “실제로 사람이 쓰기 편한 형식”은 전혀 다는거.
raw diff를 그대로 넣었던 초기 버전은 정확하긴 했지만, 막상 내가 QA 입장에서 읽으려고 하니 너무 피곤했거든요.
그래서 요약과 분류를 붙여주자 비로소 “이제야 실무에서 써먹을 수 있겠다”는 느낌이 적인 느낌.
가장 큰 효화는 모든 테스트에 동일한 변환 엔진을 적용하니:
- 코드 유지보수가 쉬워짐
- 테스트별 결과 분석 방식이 통일됨
- 새로운 테스트 추가할 때도 같은 로직으로 처리 가능
단순히 기술적으로 “변환 가능”한 것과 “실제로 사용할 수 있는 형식”은 다르다는 거였죠.
검증: 실제로 잘 작동하는가
변환된 JUnit XML을 검증하기 위해 다음을 확인했어요.
python3 convert_to_junit.py regression.out regression.diffs
생성된 XML을 파싱해서:
- 모든 테스트가 정확히 변환되었는지
- 실패 메시지가 의도대로 생성되었는지
- XML 포맷이 valid한지
전체 코드를 첨부해드려요
python3.12 이상이면 추가 pip 패키지 설치없이 실행가능합니다.
import sys
import re
import os
import xml.etree.ElementTree as ET
from xml.dom import minidom
from datetime import datetime
def clean_xml_string(s):
"""
Removes characters that are invalid in XML.
"""
if s is None:
return ""
illegal_chars_re = re.compile(u'[\x00-\x08\x0b\x0c\x0e-\x1f\ufffe\uffff]')
return illegal_chars_re.sub('', s)
def summarize_diff(diff_content):
"""
Analyzes diff content and creates a human-readable summary.
Returns (summary_string, list_of_mismatches)
"""
if not diff_content:
return "", []
summary = []
errors = []
mismatches = []
lines = diff_content.splitlines()
i = 0
while i < len(lines):
line = lines[i]
# 1. Look for Errors
if "ERROR:" in line:
errors.append(line.strip())
# 2. Look for Value Mismatches (Look for consecutive - and + blocks)
# Standard diff format: '-' or '+' followed by the line content.
if line.startswith("-") and not line.startswith("---"):
expected_block = []
while i < len(lines) and lines[i].startswith("-") and not lines[i].startswith("---"):
expected_block.append(lines[i][1:])
i += 1
actual_block = []
while i < len(lines) and lines[i].startswith("+") and not lines[i].startswith("+++"):
actual_block.append(lines[i][1:])
i += 1
if expected_block or actual_block:
expected = "\n".join(expected_block).strip()
actual = "\n".join(actual_block).strip()
# If they are just separators, skip if both are just dashes
if expected.startswith("--") and actual.startswith("--"):
continue
if expected != actual:
mismatches.append((expected, actual))
continue # Already incremented i
i += 1
if errors:
summary.append("[RUNTIME ERRORS]")
for err in list(dict.fromkeys(errors))[:5]: # Unique, max 5
summary.append(f" ! {err}")
summary.append("")
if mismatches:
summary.append("[VALUE MISMATCHES]")
for exp, act in mismatches[:10]: # Max 10
summary.append(f" - EXPECTED: {exp[:200] + '...' if len(exp) > 200 else exp}")
summary.append(f" + ACTUAL: {act[:200] + '...' if len(act) > 200 else act}")
summary.append(" " + "-"*20)
if len(mismatches) > 10:
summary.append(f" ... and {len(mismatches) - 10} more mismatches.")
summary.append("")
if not summary:
if "QUERY PLAN" in diff_content:
summary.append("[PLAN CHANGE] Query execution plan has changed.")
else:
summary.append("[GENERAL FAILURE] Output does not match expected result.")
summary.append("")
return "\n".join(summary), mismatches
def parse_regression_diffs(diff_file):
"""
Parses regression.diffs and returns a mapping of test name to its diff content.
"""
diffs = {}
if not os.path.exists(diff_file):
return diffs
current_test = None
current_content = []
# Example header: diff -U3 .../expected/test_name.out .../results/test_name.out
pattern = re.compile(r'^diff -U\d+ .*?/(?:expected|ora_expected)/(.+?)\.out .*?/results/\1\.out')
with open(diff_file, 'r', errors='replace') as f:
for line in f:
match = pattern.match(line)
if match:
if current_test:
diffs[current_test] = "".join(current_content)
current_test = match.group(1)
current_content = [line]
elif current_test:
current_content.append(line)
if current_test:
diffs[current_test] = "".join(current_content)
return diffs
def get_test_output(test_name, results_dir):
"""
Reads the actual output file for a test from the results directory.
"""
log_path = os.path.join(results_dir, f"{test_name}.out")
if os.path.exists(log_path):
try:
with open(log_path, 'r', errors='replace') as f:
return f.read()
except:
return f"Error reading log file at {log_path}"
return f"Actual output file not found at {log_path}"
def parse_regression_out(file_path):
"""
Parses regression.out and returns a list of test case dictionaries.
"""
test_cases = []
current_group = "Default Group"
pattern = re.compile(r'^(ok|not ok)\s+(\d+)\s+([-+])\s+(\S+)\s+(\d+)\s+ms')
with open(file_path, 'r') as f:
for line in f:
line = line.strip()
if not line:
continue
if line.startswith("# parallel group"):
group_match = re.search(r'# (parallel group \(.*?\))', line)
if group_match:
current_group = group_match.group(1)
else:
current_group = line[1:].split(":")[0].strip()
continue
match = pattern.match(line)
if match:
status = match.group(1)
test_name = match.group(4)
duration = int(match.group(5)) / 1000.0
test_cases.append({
'name': test_name,
'classname': current_group,
'time': str(duration),
'status': status
})
return test_cases
def get_out_file_steps(filepath):
"""
Parses a PostgreSQL .out file and returns a list of dictionaries,
each containing the SQL statement and its line range.
"""
if not os.path.exists(filepath):
return []
steps = []
current_sql = []
start_line = 1
sql_keywords = ('SELECT', 'INSERT', 'UPDATE', 'DELETE', 'CREATE', 'DROP',
'ALTER', 'CALL', 'DO', '\\', 'BEGIN', 'COMMIT', 'ROLLBACK', '-- ')
with open(filepath, 'r', errors='replace') as f:
lines = f.readlines()
for i, line in enumerate(lines):
stripped = line.strip()
# Heuristic for new command: starts with keyword at beginning of line
is_new = any(line.startswith(kw) for kw in sql_keywords) and not line.startswith(' ')
if is_new:
if current_sql:
# Save previous step
steps.append({
'sql': "\n".join(current_sql).strip(),
'start': start_line,
'end': i # previous line
})
current_sql = [line.rstrip()]
start_line = i + 1
elif current_sql:
current_sql.append(line.rstrip())
if current_sql:
steps.append({
'sql': "\n".join(current_sql).strip(),
'start': start_line,
'end': len(lines)
})
return steps
def create_junit_xml(test_cases, diffs, results_dir, output_path, expected_dir, ora_expected_dir):
"""
Creates the JUnit XML file with embedded steps and results.
"""
testsuites = ET.Element('testsuites')
testsuite = ET.SubElement(testsuites, 'testsuite', {
'name': 'PostgreSQL Regression Tests',
'tests': str(len(test_cases)),
'failures': str(len([t for t in test_cases if t['status'] == 'not ok'])),
'errors': '0',
'skipped': '0'
})
for tc in test_cases:
testcase = ET.SubElement(testsuite, 'testcase', {
'name': tc['name'],
'classname': tc['classname'],
'time': tc['time']
})
actual_output = clean_xml_string(get_test_output(tc['name'], results_dir))
sys_out = ET.SubElement(testcase, 'system-out')
sys_out.text = actual_output
if tc['status'] == 'not ok':
diff_content = diffs.get(tc['name'], "")
# Find expected/actual files
actual_file = os.path.join(results_dir, f"{tc['name']}.out")
expected_file = os.path.join(expected_dir, f"{tc['name']}.out")
if not os.path.exists(expected_file):
expected_file = os.path.join(ora_expected_dir, f"{tc['name']}.out")
actual_steps = get_out_file_steps(actual_file)
expected_steps = get_out_file_steps(expected_file)
failure = ET.SubElement(testcase, 'failure', {
'message': 'Test failed',
'type': 'Failure'
})
failure_lines = [f"[FAIL] {tc['name']}\n"]
# Parse diff hunks to align failures with steps
hunks = []
if diff_content:
# Find @@ -exp_start,exp_len +act_start,act_len @@
hunk_pattern = re.compile(r'^@@ -(\d+),?(\d*) \+(\d+),?(\d*) @@')
current_hunk = None
for line in diff_content.splitlines():
match = hunk_pattern.match(line)
if match:
if current_hunk: hunks.append(current_hunk)
current_hunk = {
'exp_start': int(match.group(1)),
'act_start': int(match.group(3)),
'lines': []
}
elif current_hunk:
current_hunk['lines'].append(line)
if current_hunk: hunks.append(current_hunk)
# For each hunk, map it to a step in actual_steps
mismatching_steps = []
for hunk in hunks:
# Find the step that contains act_start
target_step = None
for step in actual_steps:
if step['start'] <= hunk['act_start'] <= step['end']:
target_step = step
break
if target_step:
# Find corresponding expected step (usually same SQL)
exp_step = None
for es in expected_steps:
if es['sql'] == target_step['sql']:
exp_step = es
break
# Extract expected and actual results specifically for this step hunk
# For simplicity, we can just show the hunk content or the whole step
exp_val = []
act_val = []
for line in hunk['lines']:
if line.startswith('-'): exp_val.append(line[1:])
elif line.startswith('+'): act_val.append(line[1:])
mismatching_steps.append({
'sql': target_step['sql'],
'expected': "\n".join(exp_val).strip() or "(no expected output for this hunk)",
'actual': "\n".join(act_val).strip() or "(no actual output for this hunk)"
})
if mismatching_steps:
# Add human-readable summary to the failure text
for idx, m in enumerate(mismatching_steps[:10]):
failure_lines.append(f"STEP {idx+1}: {m['sql']}")
failure_lines.append(f"EXPECTED:\n{m['expected']}")
failure_lines.append(f"ACTUAL:\n{m['actual']}")
failure_lines.append("-" * 40)
if len(mismatching_steps) > 10:
failure_lines.append(f"... and {len(mismatching_steps) - 10} more mismatching steps.")
# Add structured XML elements for each mismatching step
# This allows the UI to show them in a tabbed or table format
steps_elem = ET.SubElement(failure, 'steps')
for idx, m in enumerate(mismatching_steps):
step_elem = ET.SubElement(steps_elem, 'step', {'index': str(idx+1)})
sql_elem = ET.SubElement(step_elem, 'sql')
sql_elem.text = clean_xml_string(m['sql'])
exp_elem = ET.SubElement(step_elem, 'expected')
exp_elem.text = clean_xml_string(m['expected'])
act_elem = ET.SubElement(step_elem, 'actual')
act_elem.text = clean_xml_string(m['actual'])
# For compatibility with some viewers that expect top-level expected/actual
if idx == 0:
comp_exp = ET.SubElement(failure, 'expected')
comp_exp.text = clean_xml_string(m['expected'])
comp_act = ET.SubElement(failure, 'actual')
comp_act.text = clean_xml_string(m['actual'])
else:
summary, _ = summarize_diff(diff_content)
failure_lines.append(summary)
failure.text = clean_xml_string("\n".join(failure_lines))
xml_str = ET.tostring(testsuites, encoding='utf-8')
try:
reparsed = minidom.parseString(xml_str)
pretty_xml_str = reparsed.toprettyxml(indent=" ")
except Exception as e:
pretty_xml_str = xml_str.decode('utf-8')
with open(output_path, 'w', encoding='utf-8') as f:
f.write(pretty_xml_str)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python3 convert_to_junit.py <regression.out> [regression.diffs]")
sys.exit(1)
reg_out = sys.argv[1]
reg_diffs = sys.argv[2] if len(sys.argv) > 2 else "regression.diffs"
base_dir = os.path.dirname(reg_out) or "."
results_dir = os.path.join(base_dir, "results")
expected_dir = os.path.join(base_dir, "expected")
ora_expected_dir = os.path.join(base_dir, "ora_expected")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_file = f"pg_test_result_make_check_{timestamp}.xml"
results = parse_regression_out(reg_out)
diff_map = parse_regression_diffs(reg_diffs)
create_junit_xml(results, diff_map, results_dir, output_file, expected_dir, ora_expected_dir)
print(f"Successfully converted results to {output_file}")
지금 생각해보니
처음에는 단순한 변환 도구라고 생각했는데, 실제로 해보니 훨씬 복잡했어요.
문제는:
- 테스트 결과를 읽기 어려움
- 실패 원인 분석이 오래 걸림
- 여러 테스트를 한눈에 파악 불가능
이었고,
해결책은:
- 구조화된 XML 형식 사용
- 실패 원인 분류 및 요약
- 메타데이터 활용
이었습니다.
특히 자동화 도구는 “정확성”도 중요하지만 “사용성”이 더 중요해요. 아무리 정확한 데이터도 읽기 어렵고 해석하기 힘들면 소용이 없으니까요.
혹시 비슷한 문제를 겪고 있다면, 이 글이 도움이 됐으면 좋겠어요!
그럼 여기까지입니다. 끝!
관련 링크:
- PostgreSQL 테스트 문서: https://www.postgresql.org/docs/current/regress.html
- JUnit: https://github.com/junit-team/junit-framework
그럼 오늘도 여기까지 끝..